wordpress_sites:
main-site.test:
site_hosts:
- canonical: main-site.test
local_path: "/home/tackettz/projects/wordpress/sites/main-site.dev" # path targeting local Bedrock site directory (relative to Ansible root)
db_import: ./sql-backups/main-site.2017-07-13.sql
repo: ssh://git@git.oit.ohio.edu:7999/oulib/wp-site-main.git
theme: "wp-theme-main"
site_install: false
site_title: OU Libraries (Dev)
admin_user: admin
admin_password: admin
admin_email: tackettz@ohio.edu
multisite:
enabled: false
ssl:
enabled: false
cache:
enabled: false
env:
wp_home: http://main-site.test
wp_siteurl: http://main-site.test/wp
wp_env: development
db_name: main-site
db_user: main_user
Above is my wordpress_sites.yml file for development.
Whenever I create the vagrant vm, trellis is not loading the sql backup that I am telling it to load. Whenever the vm is created it’s asking me to install WordPress which it shouldn’t because of the sql backup.
I think you’re probably encountering this change:
That thread mentions a few import alternatives.
Interesting but it doesn’t explain where the command should be run?
wp-cli commands are run in the wordpress root. For example:
vagrant ssh
cd /srv/www/main-site.test/current
wp db import /vagrant/sql-backups/main-site.2017-07-13.sql
resources:
2 Likes
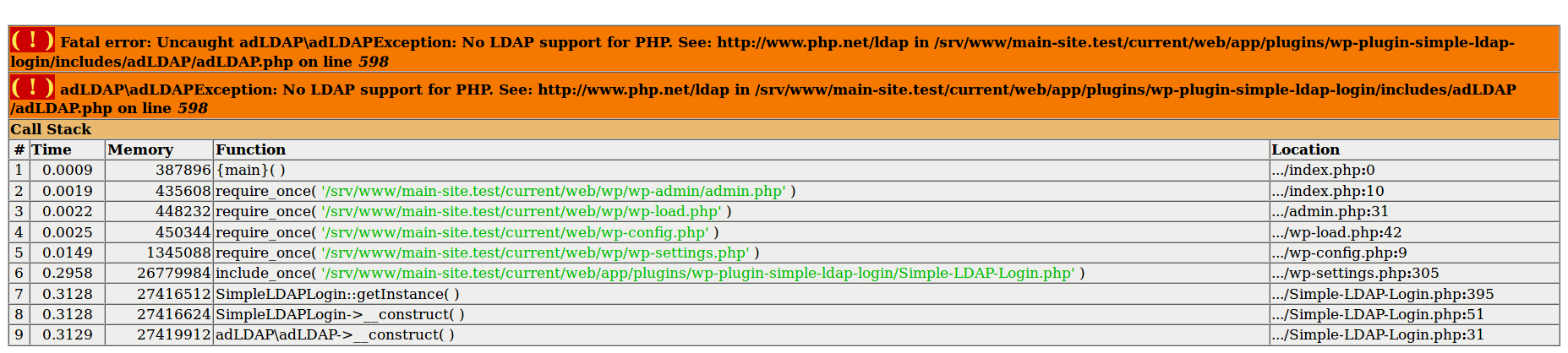
I did that and it imported successfully but now I am getting this error from a plugin for some reason.
Everything works fine when I vagrant up using rc1, but now I’m getting this.
LDAP support in PHP is not enabled by default
PHP: Installation - Manual
Try install php7.1-ldap as this stackoverflow thread suggested.
Somewhere within group_vars/all/xxx.yml:
php_extensions_custom:
php7.1-ldap: "{{ apt_package_state }}"
2 Likes
TASK [deploy : Reload php-fpm] ************************************************************************
System info:
Ansible 2.4.0.0; Linux
Trellis at “Fix failed_when in template_root check with wp-cli 1.5.0”
MODULE FAILURE
Shared connection to lib-web-lp001.mgt.private closed.
[sudo] password for tackettz:
{“changed”: true, “end”: “2018-02-15 13:51:12.030117”, “stdout”: “”, “cmd”:
“sudo service php7.1-fpm reload”, “failed”: true, “delta”: “0:05:00.369352”,
“stderr”: “”, “rc”: 1, “invocation”: {“module_args”: {“warn”: false,
“executable”: null, “_uses_shell”: true, “_raw_params”: “sudo service
php7.1-fpm reload”, “removes”: null, “creates”: null, “chdir”: null, “stdin”:
null}}, “start”: “2018-02-15 13:46:11.660765”, “msg”: “non-zero return code”}
fatal: [www-test]: FAILED! => {“changed”: false, “failed”: true, “rc”: 0}
to retry, use: --limit @/home/tackettz/environments/trellis-rc2/deploy.retry
PLAY RECAP ********************************************************************************************
localhost : ok=0 changed=0 unreachable=0 failed=0
www-test : ok=38 changed=15 unreachable=0 failed=1
The deploy stalls/hangs at this task, and then fails with this output after a few minutes
Here is with -vvvv
System info:
Ansible 2.4.0.0; Linux
Trellis at “Fix failed_when in template_root check with wp-cli 1.5.0”
MODULE FAILURE
OpenSSH_7.2p2 Ubuntu-4ubuntu2.2, OpenSSL 1.0.2g 1 Mar 2016
debug1: Reading configuration data /home/tackettz/.ssh/config
debug1: /home/tackettz/.ssh/config line 1: Applying options for *
debug1: /home/tackettz/.ssh/config line 17: Applying options for www-test
debug1: Reading configuration data /etc/ssh/ssh_config
debug1: /etc/ssh/ssh_config line 19: Applying options for *
debug1: auto-mux: Trying existing master
debug2: fd 3 setting O_NONBLOCK
debug2: mux_client_hello_exchange: master version 4
debug3: mux_client_forwards: request forwardings: 0 local, 0 remote
debug3: mux_client_request_session: entering
debug3: mux_client_request_alive: entering
debug3: mux_client_request_alive: done pid = 9213
debug3: mux_client_request_session: session request sent
debug1: mux_client_request_session: master session id: 2
debug3: mux_client_read_packet: read header failed: Broken pipe
debug2: Received exit status from master 0
Shared connection to lib-web-lp001.mgt.private closed.
[sudo] password for tackettz:
{“changed”: true, “end”: “2018-02-15 14:04:30.353984”, “stdout”: “”, “cmd”:
“sudo service php7.1-fpm reload”, “failed”: true, “delta”: “0:05:00.266644”,
“stderr”: “”, “rc”: 1, “invocation”: {“module_args”: {“warn”: false,
“executable”: null, “_uses_shell”: true, “_raw_params”: “sudo service
php7.1-fpm reload”, “removes”: null, “creates”: null, “chdir”: null, “stdin”:
null}}, “start”: “2018-02-15 13:59:30.087340”, “msg”: “non-zero return code”}
fatal: [www-test]: FAILED! => {
“changed”: false,
“failed”: true,
“rc”: 0
}
to retry, use: --limit @/home/tackettz/environments/trellis-rc2/deploy.retry
PLAY RECAP *************************************************************************************************************************************************************************************************
localhost : ok=0 changed=0 unreachable=0 failed=0
www-test : ok=38 changed=15 unreachable=0 failed=1
I wouldn’t have expected to see [sudo] password for tackettz in the output.
- It makes me wonder if you’ve changed the
web_user to tackettz. Doing so should be fine.
- If it is prompting for a sudo password, it makes me think that this task hasn’t run for your latest
web_user. The task enables the web_user to reload php without a sudo password. Could you rerun the server.yml playbook to ensure the web_user is fully configured, then try another deploy with deploy.yml?
If something new arises and you’re unable to resolve it on your own by searching discourse and Trellis docs, go ahead and start a new thread. We try to keep each thread focused on a single issue.
is it required to provision the staging/production servers before deploying after each new trellis update?
I have web_user set to {{ ssh_user }}
Some Trellis updates may necessitate running server.yml before your next deploy, some may not. It’s easiest to just run both server.yml and deploy.yml after a Trellis update.
However, you could check what code has changed and what minimal command is needed to apply the change. For example, suppose you update your Trellis just to obtain some minor php config fix. In that case you could just run something more targeted:
ansible-playbook server.yml -e env=production --tags php
Ok, I’m not aware of any Trellis variable or built-in Ansible variable {{ ssh_user }} but maybe you’ve defined that somewhere.
It will be interesting to see if at minimum server.yml with --tags users would resolve the problem with php reload on deploys, especially if you haven’t run server.yml since customizing the web_user definition.
If the php reload problem persists, you might share who is your hosting provider (e.g., DigitalOcean etc.). If the system you’re deploying to is managed by someone else at all, you might check with them regarding potential restrictions on passwordless sudo.
To get around the problem in the short term, you could ssh into the server after deploy and
sudo service php7.1-fpm reload
(as root or as the admin_user).
1 Like
I’m closing this thread since it was originally about a DB import which was solved.
If you still have an issue, then please create a new thread with details specifically for it