I have a problem with a new project with Trellis. When starting the virtual machine I can work without problems for a few minutes, but then the server freezes. I can not do anything. I can’t shut down the server normally either. The trellis down command should force a shutdown after a while of trying graceful shutdown.
==> default: Attempting graceful shutdown of VM...
==> default: Forcing shutdown of VM...
Has this happened to anyone? What would you look at to debug it?
I bet that’s really helping your workflow From the format of the log message, I guess you’re using Vagrant, not Lima?
I would start by:
Determine which layer is freezing. Is it the VM itself, or the hypervisor? If you have other VMs running, do they continue to be responsive when the Trellis VM freezes? If the issue lies in at the hypervisor level, please share version information for Vagrant / VirtualBox etc.
If VM based, try looking at dmesg from the previous boot. I think Ubuntu has journalctl. So try journalctl -o short-precise -k -b -1. You may be able to spot some obvious entries - OOM or similar.
Yes I’m experiencing the same in my latest project using Trellis v1.20.0.
I’m on a M1 MacBook with macOS Ventura 13.2.1 running Vagrant 2.3.4 in Parallels Desktop 18.2.0.
It’s hard to determine when it exactly happens, but it seems to trigger on a theme change during bud dev. I check the VM error logs but there’s nothing in there referring to the time of freeze.
At that point I can only do a vagrant reload -f to reboot and all is good again, but it’s getting a bit frustrating. When it freezes I can still access the database fortunately.
The /etc/hosts/ & /etc/exports are also still in place and correct.
I don’t have other VM’s running at the same time, so how would one check if the issue lies on the hypervisor level?
It’s only happening in this project and I already tried destroying & recreating the VM box multiple times but this issue keeps coming back.
Thanks for the useful info. It sounds to me like the issue resides on the VM itself, because you have identified a VM-based trigger - bud dev.
This would lead me to suspect an OOM condition, even if MySQL is up after the freeze (the kernel will make decisions about which processes to kill in the event of OOM, and it could decide to leave your mysqld up, but take down your tty / shell / bud).
After restarting the VM after a freeze. See what output you get from:
journalctl -o short-precise -k -b -1
(You can adjust the last arg to look back across multiple boots (-1 is last boot, -2 is boot before last etc.). If you see a reference to killed process, it’s likely a memory issue.
To increase the VM’s memory allocation from within Trellis, try creating a vagrant.default.yml file containing at least:
vagrant_memory: 2048 # Increase VM's memory to 2GiB
You’ll likely need to vagrant destroy && vagrant up for that change to take effect, but perhaps not. It’s been a while since I’ve used Vagrant!
That’s interesting - so the VM is failing to communicate with your host machine’s NFS server on 192.168.56.1.
This kind of error would usually suggest a network interruption in the case of a traditional NFS setup (ie. over physical link) or perhaps nfsd is quitting for some reason.
Is there any reason why your network configuration may change or interfaces be stopped / started while you are using the VM? Perhaps VPN software, or similar?
nfsd on OSX seems to log via syslog() so is there anything NFS related in there? Try checking /private/var/log/system.log (on your host machine) for NFS related messages. I’d probably run tail -f /private/var/log/system.log | grep nfs and then try and make a VM crash.
You may also find the OSX syslog at /var/log/system.log
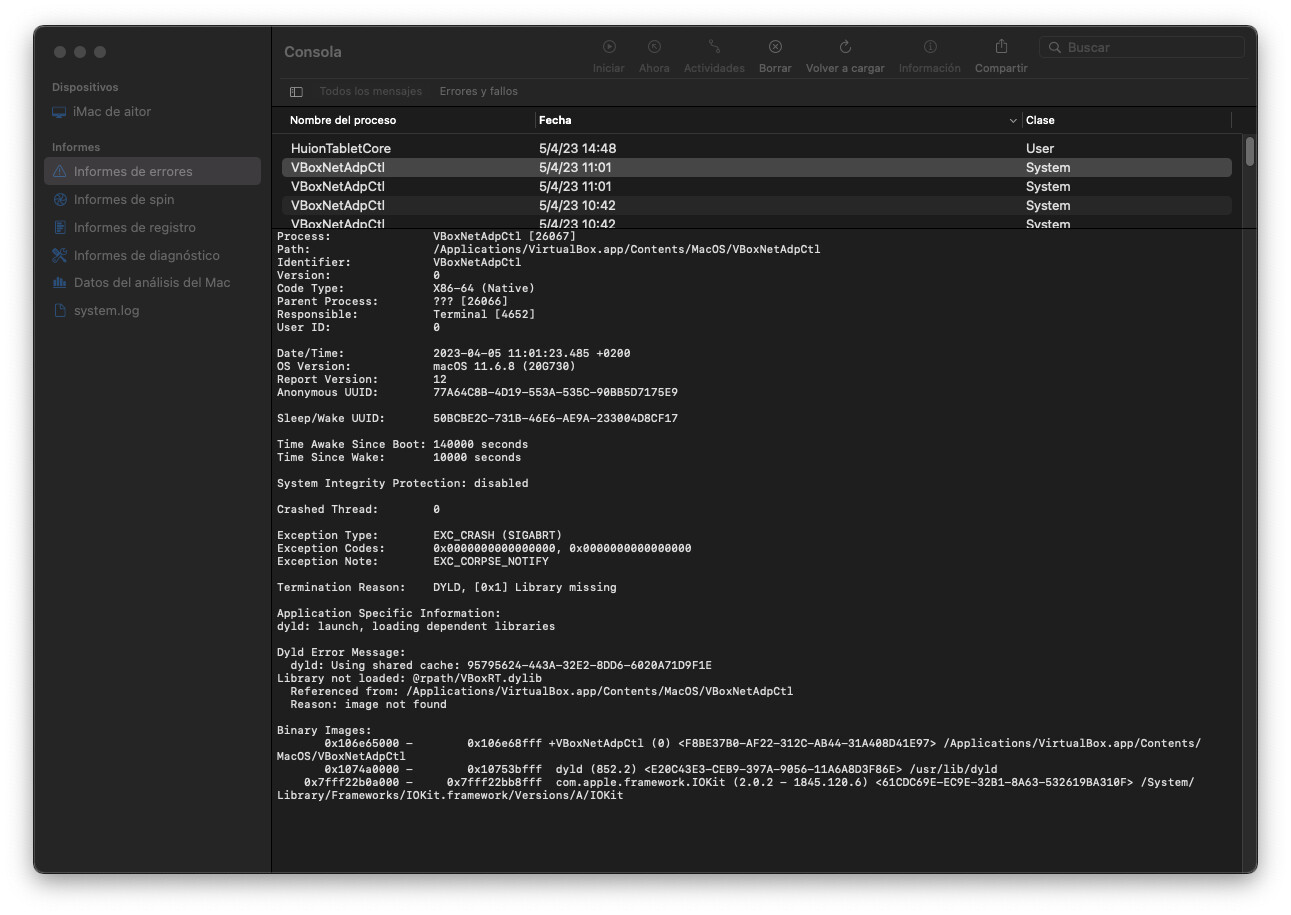
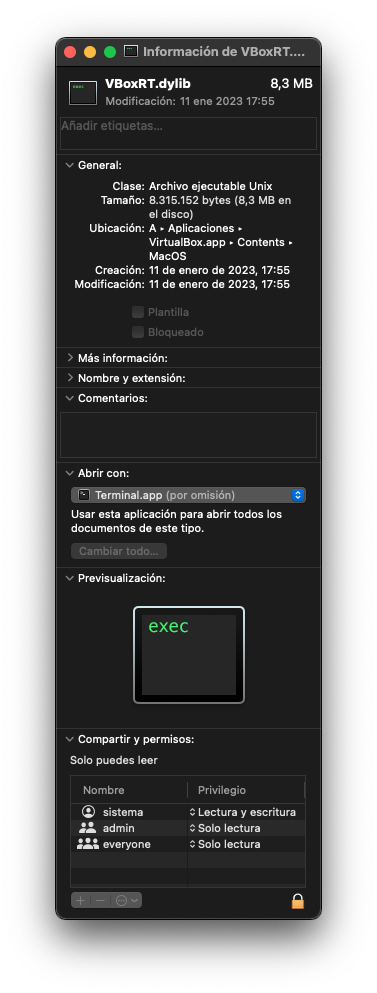
This might be a permissions issue. It’s probably a good time to reinstall VirtualBox and see if that fixes things. If not - does /Applications/VirtualBox.app/Contents/MacOS/VBoxRT.dylib exist and who owns / what permissions?
I can’t reach a file inside application content with the terminal (I don’t know how), but I can use the GUI to see it, is that enough? In file is there and has read and write permission for system.
The first time the bug appeared I reinstalled VBox updating to the latest version and the problem persists.
It’s often not a good thing to recommend a different technology to solve a problem with another one… but it might be worthwhile giving trellis-cli’s new VM integration a try because it entirely avoids NFS, which is a very common issue with VMs.
See Local Development | Trellis Docs | Roots for more info. There’s a section on migrating as well; so you don’t need to fully commit to moving off Vagrant. You can try out both (just not at the exact same time).
Thank you. That sounds good. I have tried to use it but it does not support my OS (Big Sur). I’m having trouble upgrading to Ventura on my hackintosh. I’ll have to dedicate a few days to that matter, finally.
Thanks for your reply! I had to wait a bit before another freeze happened
After rebooting I ran the journalctl command but I can’t see any killed process lines.
The freeze just happened around 11:17 and the last line of the last boot was at 10:12.
The system.log also doesn’t show any info about nfs when running: tail -f /private/var/log/system.log | grep nfs
In /Library/logs/parallels.log I only see this line around the time of freeze:
04-06 11:17:40.759 F /pvsHostInfo:620:1d28/ hw.cpufrequency error = 2
But that hw.cpufrequency error is in there a lot.
Not sure what else to check?
Just another freeze, this time the journalctl has this at the end:
Apr 06 11:23:27.761941 ona kernel: FS-Cache: Loaded
Apr 06 11:23:27.777950 ona kernel: FS-Cache: Netfs 'nfs' registered for caching
Apr 06 11:27:04.054052 ona kernel: nfs: server 10.211.55.2 not responding, still trying
So similar as @aitor’s.
But I’m using Parallels Desktop and not Virtualbox?
In /etc/hosts this project is the only one that has this line added after:
I’m facing the same problem and have to perform a vagrant reload every 30 mins or so. Unfortunately, Lima isn’t an option for me because I can’t run Ventura on my Late 2015 iMac :-/
On top of that, I’m not able to connect to the ipv4 address either.
Did anyone find a solution/fix for this in the end?
This keeps happening for me, for this one particular project only with trellis version 1.20.0.
I destroyed and re-created my dev box, but same thing unfortunately…