Catching up on the great work done here, im giving this a go on windows, with babun, zsh.
Some things / questions / wonders arise.
Here’s what i did:
Cloned trellis/master into Trellis directory
Cloned Bedrock into site directory
cd into trellis <-- missing from docs
Ran vagrant up [ansible should run on the VM when host is windows]
*Unchanging default values for a first time run, since i want to first see i get how this comes together.
Good.
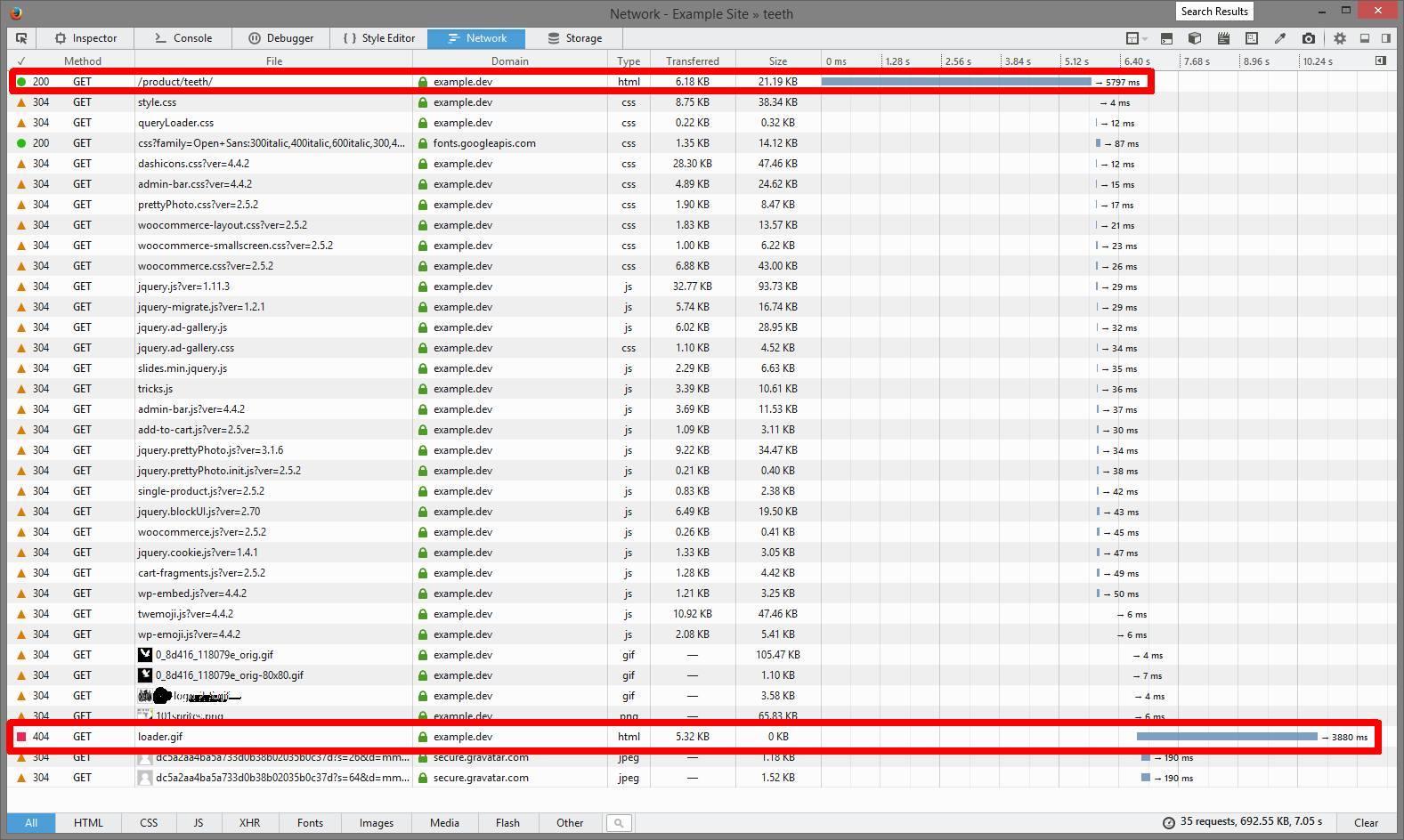
Hat off - the site loads and runs fine, albeit a bit slower than another vagrant box i have on the same laptop. [pages take 2-3 seconds to load on the trellis provisioned box, as opposed to <1sec on a vvv provisioned one ]
Why daemonize ? What is it’s purpose here, and do i now find any mention to it in the repo ?
I get a few red lines from vagrant up / provision
Errors:
==> default: dpkg-preconfigure: unable to re-open stdin: No such file or directory
==> default: TASK [wordpress-setup : Template files out to includes.d] **********************
==> default: /bin/sh: 1: cd: can't cd to /vagrant/roles/wordpress-setup/templates/includes.d
3 . Even though i can ssh just fine into the box, i get the ssh-forwarding note - why?
I followed the GitHub guide although i am not sure i needed to, as i was able to login to other vagrant boxes without it, and also make scp requests to other servers on the nets…
4 . Ansible does something even though nothing changed in the config files? ;
Many questions but this system does make me ask them…
I am going to try some more tests now. Would extremely appreciate any light you can shed on these issues.
daemonize is a dependency of the mailhog role that we pull in from Ansible Galaxy. That’s why you don’t need any reference to it in our codebase :). If you did grep -r 'daemonize' . (on the VM in your case) then you’d see it.
I haven’t seen that message before. If you do any further debugging please let us know.
I believe that warning is there because deploys need SSH forwarding. It doesn’t matter for development though. Maybe the message could be improved. /cc @QWp6t
You’re right that changed should be 0 on subsequent provisions. I believe there’s 1 or 2 bugs in core Ansible modules which causes this problem. There isn’t much we can do unfortunately until it’s fixed upstream.
Yeah, the SSH forwarding note is there in case you want to provision a remote server or deploy to one. You probably won’t be able to do that without proper SSH forwarding.
For using a different MTA, woulnd have to change requirements.yml, and get roles for that one, right?
What output is expected from ls -la /vagrant/roles/wordpress-setup/templates/includes.d on a freshly provisioned box? roles/wordpress-setup/nginx.yml refers to templates/include.d/ and tries to cd into it, but it ain’t there…
Thanks for commenting @QWp6t
One thing is the message is injected to .profile on each provision i end up with quite a few mentions to a link that doesn’t actually fix the issue.
Moreover, now initial page wait for each page load is up to 5 seconds !
@daadir The includes.d directory is optional, for when you have Nginx includes. The || : at the end of the commandcd <includes.d path> && <do stuff> || : causes the command to still return a 0 (non-error) exit status when includes.d is missing, so the playbook won’t fail/halt.
The Nginx includes feature was developed with Ansible 1.x, which didn’t print the can't cd to... message, but Ansible 2.x does. The next revision of the Nginx includes feature could switch some of those tasks to run only when includes.d is present, avoiding the error and the message. In the meantime, you can just ignore the message.
As for the dpkg-preconfigure error you mentioned in your original post, it looks like there are a number of google results, which perhaps you’ve explored already.
if the box just came up now, it would take 2-3 seconds of wait for served resources. If its running longer, it could
take 6 seconds of initial wait time. I tried this also with twenty fifteen, its the same - why like this?
Is there a good way to test where the slooowness is coming from?
The Nginx includes feature is for including conf files into your site’s Nginx conf here. I’m not aware of examples out there. I’ve used it once to include some redirects. I created a list variable like this in group_vars/all/main.yml:
redirects:
- from: slugtoredirect
to: http://othersite.com/newslug/
- from: anotherslug
to: http://someothersite.com/anotherslug
Then I created this template in roles/wordpress-setup/templates/includes.d/example.com/redirects.conf.j2:


 ]
] mentions to a link that doesn’t actually fix the issue.
mentions to a link that doesn’t actually fix the issue.